Elasticsearch入门分享

当前大数据时代伴随产生的问题之一,信息过载:指的是社会信息超过了个人或系统所能接受、处理或有效利用的范围,反而影响正常的理解与决策。信息检索(搜索引擎)是诸多解决方案中的典型代表。
诞生背景与使用场景
从Lucene到Elasticsearch
信息检索
当前大数据时代伴随产生的问题之一,信息过载:指的是社会信息超过了个人或系统所能接受、处理或有效利用的范围,反而影响正常的理解与决策。信息检索(搜索引擎)是诸多解决方案中的典型代表。
分词算法
词是信息检索的基础单位,分词算法将文档拆分成单词,每种语言都有很多的实现,这里不赘述。分词算法质量会影响信息检索的精确度。
倒排索引
在没有搜索引擎时,我们是直接输入一个网址,然后获取网站内容,这时我们的行为是:
document -> to -> words
通过文章,获取里面的单词,这种称为forward index「正向索引」
后来,我们希望能够输入一个单词,找到含有这个单词,或者和这个单词有关系的文章:
word -> to -> documents
这种索引称为inverted index,国内翻译成「倒排索引」
检索模型
检索模型是判断文档内容与用户查询相关性的核心技术,即查询结果的评分排序,这里不赘述,常见的模型有布尔检索模型、tf-idf权重计算、向量空间模型、概率检索模型。
Lucene简介
Lucene是一个开源的全文检索引擎工具包,1997年诞生,2000年成为Apache开源社区的一个子项目。
整体架构如下,主要分为两部分:输入数据建立索引;查询时通过索引进行检索。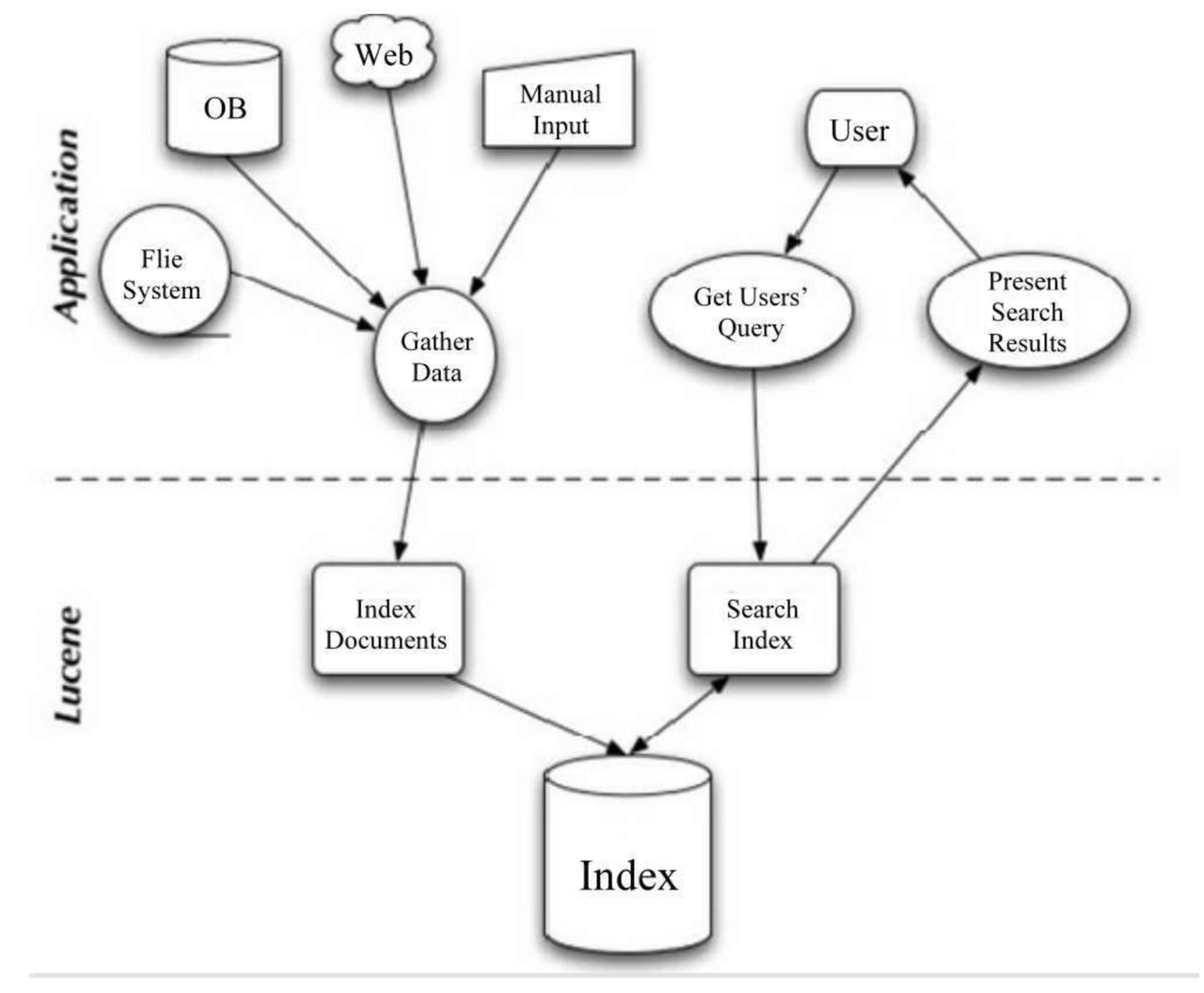
Elasticsearch概述
ES(简称),是一个基于Lucene的搜索服务器,Lucene专注于底层搜索的建设,Elasticsearch专注于企业应用。
ES具备分布式、高可用、实时等特性;其主要用于信息检索、日志分析、数据库加速等应用场景。
DB-Engines(https://db-engines.com/en/ranking )上es数据库在搜索引擎领域排名第一。
2019年社区(中国)使用者调查报告显示,Top5的应用场景如下:
- 信息检索:76.3%
- 日志分析:68.1%
- 业务数据分析:32.5%
- 数据库加速:30.2%
- 运维指标监控:29.6%
使用场景
搜索
典型场景:商品搜索
如何做搜索之用mysql:
select
fild1, fildn
from
goods
where
title like '%抖音同款%'
or content like '%抖音同款%';
存在问题:
- like %xx%无法走索引,全表扫描;
- 扩容成本大,分布式实现困难;
解决方案: - 分词 + 倒排索引
- 分布式
优化后架构: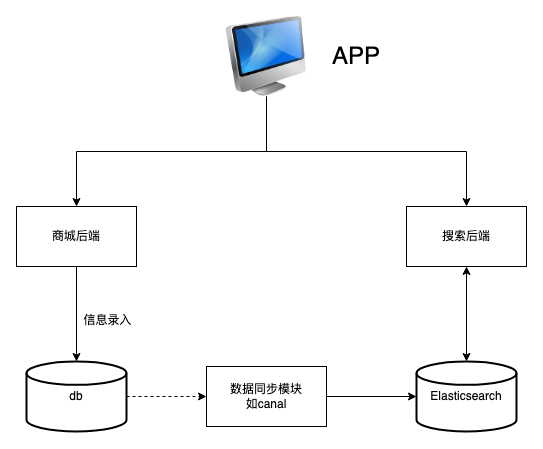
推荐
典型场景:商品搜索后的排序推荐
架构: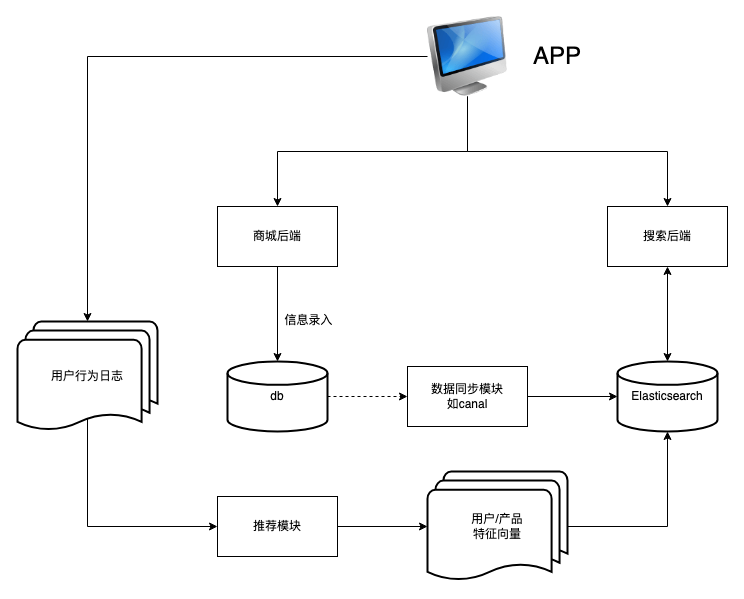
二级索引
典型场景:多维度复杂数据的联表查询优化
举例来说,在商家后台运营系统中,一条完整的账单会包含多种信息,如账单信息、开票信息,订单明细信息,店铺信息等,为了避免数据冗余,通常会创建多个表进行存储,导致多表之间的关联关系也就变的更复杂。为了更好的方便运营同学的查看数据的效率,通常会以某个维度将相关数据串联起来进行展示,这带来的一个直接问题就是连表查询。
架构同搜索场景。
日志分析
典型场景:ELK (Logstash – Elasticsearch – Kiba8na)
- Kib ana (提供监控、日志分析、性能检测、控制台)
- Elastic Search (分布式搜索引擎)
- Logstash (数据处理管道,负责收集、加工、过滤数据)
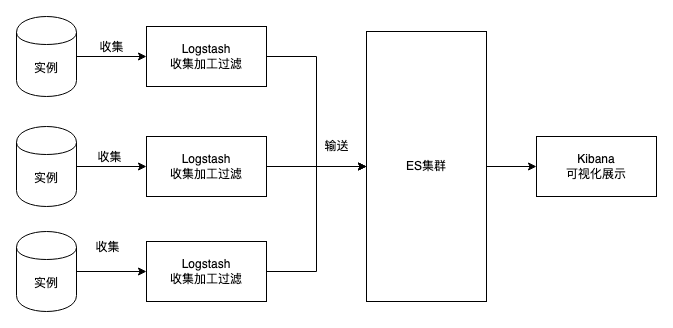
原始数据会从多个来源(包括日志、系统指标和网络应用程序)输入到 Elasticsearch 中。
数据采集指在 Elasticsearch 中进行索引之前解析、标准化并充实这些原始数据的过程。这些数据在 Elasticsearch 中索引完成之后,用户便可针对他们的数据运行复杂的查询,并使用聚合来检索自身数据的复杂汇总。
在 Kibana 中,用户可以基于自己的数据创建强大的可视化,分享仪表板,并对 Elastic Stack 进行管理。
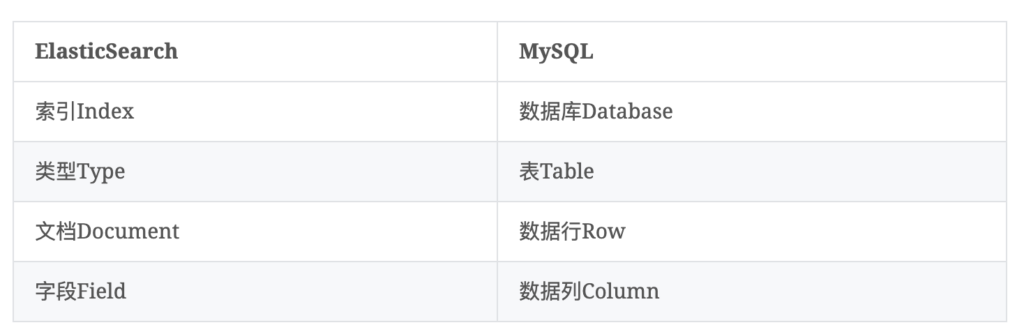
基本概念
- 索引Index:具有相同特征文档数据的集合,7.x以后一个索引只能定义一个type
- 类型Type:在索引上的一个逻辑分类/分区
- 文档Document:一个文档是一个可被索引的基础信息单元,文档以json格式表示
- 字段Field:
- 集群cluster:由多个master + data节点组成的一组服务,
- 节点node:作为集群的一部分,它存储数据参与集群的索引和搜索功能,大致分为:master节点、协调节点、数据节点
- 分片:一个索引保存了大量的文档数据,这些数据默认均匀分布在分片中,分片则分布在数据节点上,一个分片是一份完整的lucene索引
- 复制分片:是主分片的备份
原理初探
Elasticsearch倒排索引实现
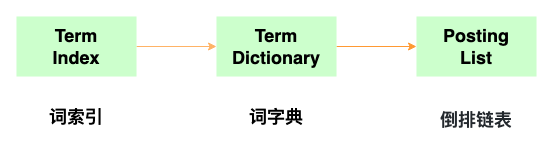
举个例子,假如我们有如下几条数据
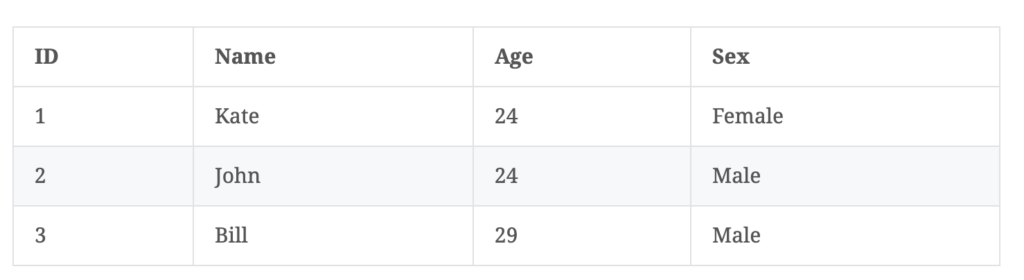
ID是Elasticsearch自建的文档id,那么Elasticsearch建立的索引如下:
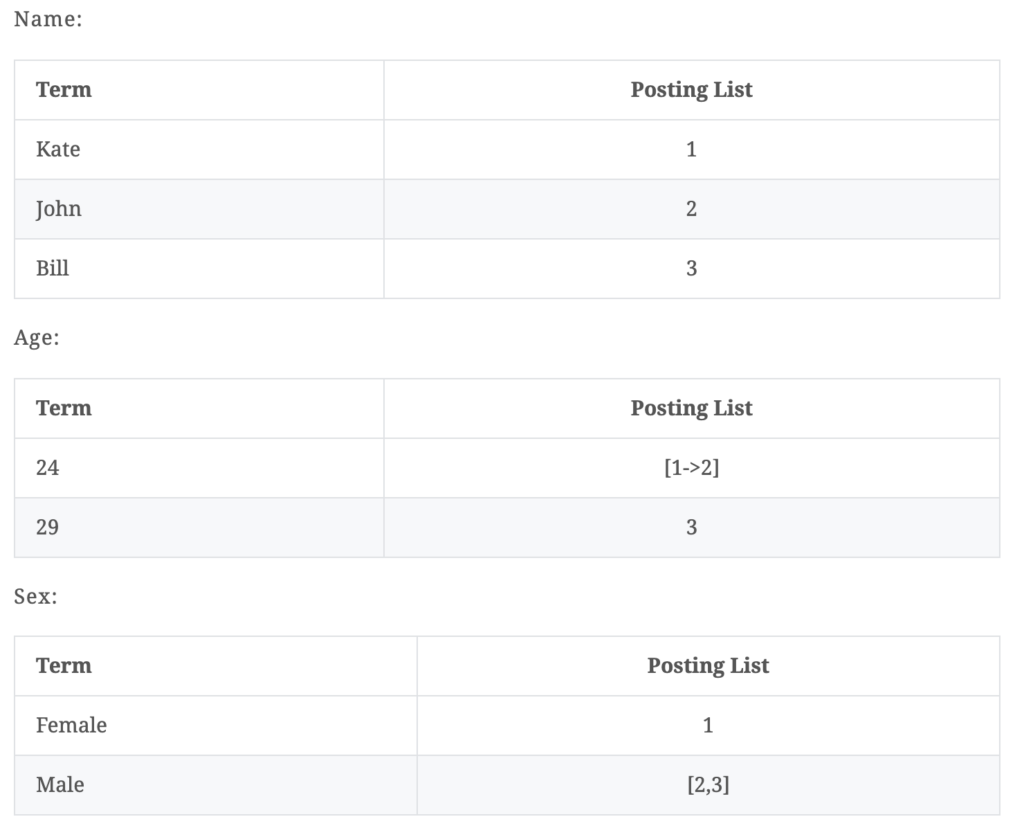
Posting List
Elasticsearch分别为每个field都建立了一个倒排索引,Kate, John, 24, Female这些叫term(词),而[1,2]就是Posting list。Posting list存储了所有符合某个term的文档id。(PS: posting list还存储了其他很多信息,比如term在该文档中出现的位置信息,词频(Term出现的次数)、偏移量(offset)等)。
ES对Posting List做了压缩,其中使用到了Delta Encoding(增量编码),先对Posting List做了排序,然后存储两个DocID之间的增量: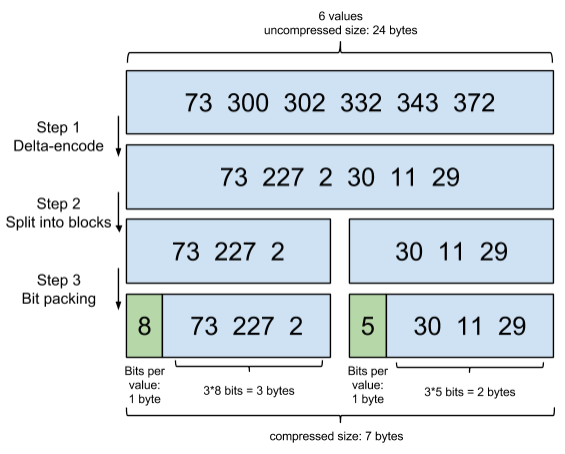
简单解读一下:
- step1:在对posting list进行压缩时进行了正序排序。
- step2:通过增量将73后面的大数变成小数存储增量值。
- step3: 转换成二进制,取占最大位的数,227占8位,前三个占八位,30占五位,后三个数每个占五位。
通过这种方式,未压缩之前需要24bytes的空间,而压缩之后仅仅需要7bytes,大幅减少了disk占用。
Term Dictionary
Elasticsearch为了能快速找到某个term,将所有的term按照字典序排序,同时还存在一个”跳表”结构按一定的间隔来记录词项,用来加速词项信息的查找。
Term Index
B-Tree通过减少磁盘寻道次数来提高查询性能,Elasticsearch也是采用同样的思路,直接通过内存查找term,不读磁盘,但是如果term太多,term dictionary也会很大,放内存不现实,于是有了Term Index,可以理解term index是一颗树: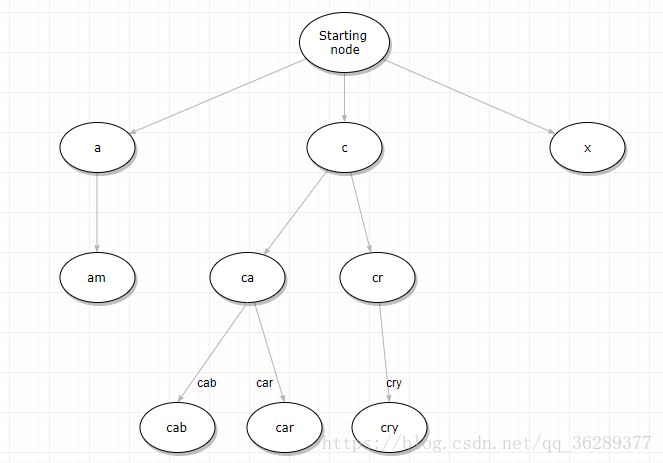
这棵树不会包含所有的term,它包含的是term的一些前缀。通过term index可以快速地定位到term dictionary的某个offset(分支的开端),然后从这个位置再往后顺序查找,再加上FST(Finite-State Transducer 有限状态传感器 ,Lucene4.0开始使用该算法来查找Term在Dictionary中的位置)的压缩技术,可以将Term Index缓存到内存中。通过Term Index找到对应的Term Diction-ary的block,然后再去磁盘直接找到term,减少磁盘的随机读写次数,大大的提升查询效率。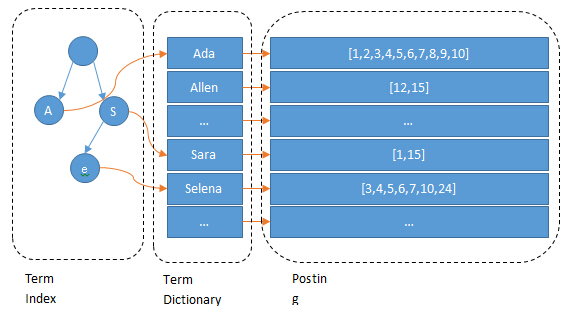
数据操作流程
Elasticsearch 是基于 Lucene 实现的,其关系可以用如下图来表示。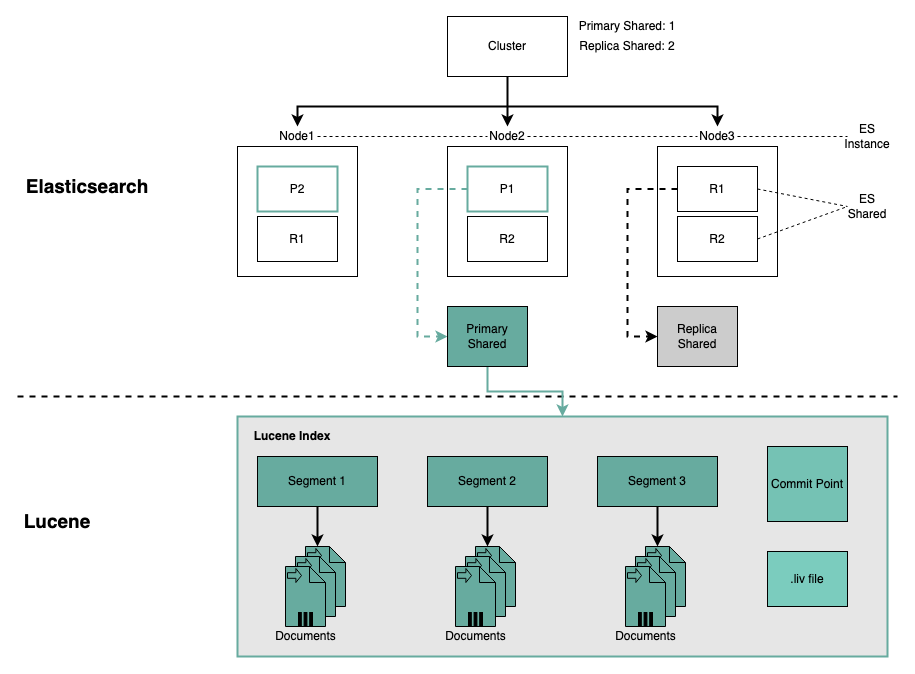
- 一个 ES集群下,有多个 Node (节点)组成。每个节点就是 ES 的实例。
- 每个节点上会有多个 shard (分片), P1 P2 是主分片 R1 R2 是副本分片
- 每个分片上对应着就是一个 Lucene Index(底层索引文件)
- Lucene Index 是一个统称。由多个 Segment (段文件,就是倒排索引)组成。每个段文件存储着就是 Doc 文档。
- 每个Lucene Index 中的 point 文件记录了所有 segments 的信息
- 文档 create 新写入时,会生成新的 segment。同样会记录到 commit point 里面
- 文档查询,会查询所有的 segments
- 当一个段存在文档被删除,会维护该信息在 .liv 文件里面
文档写入流程
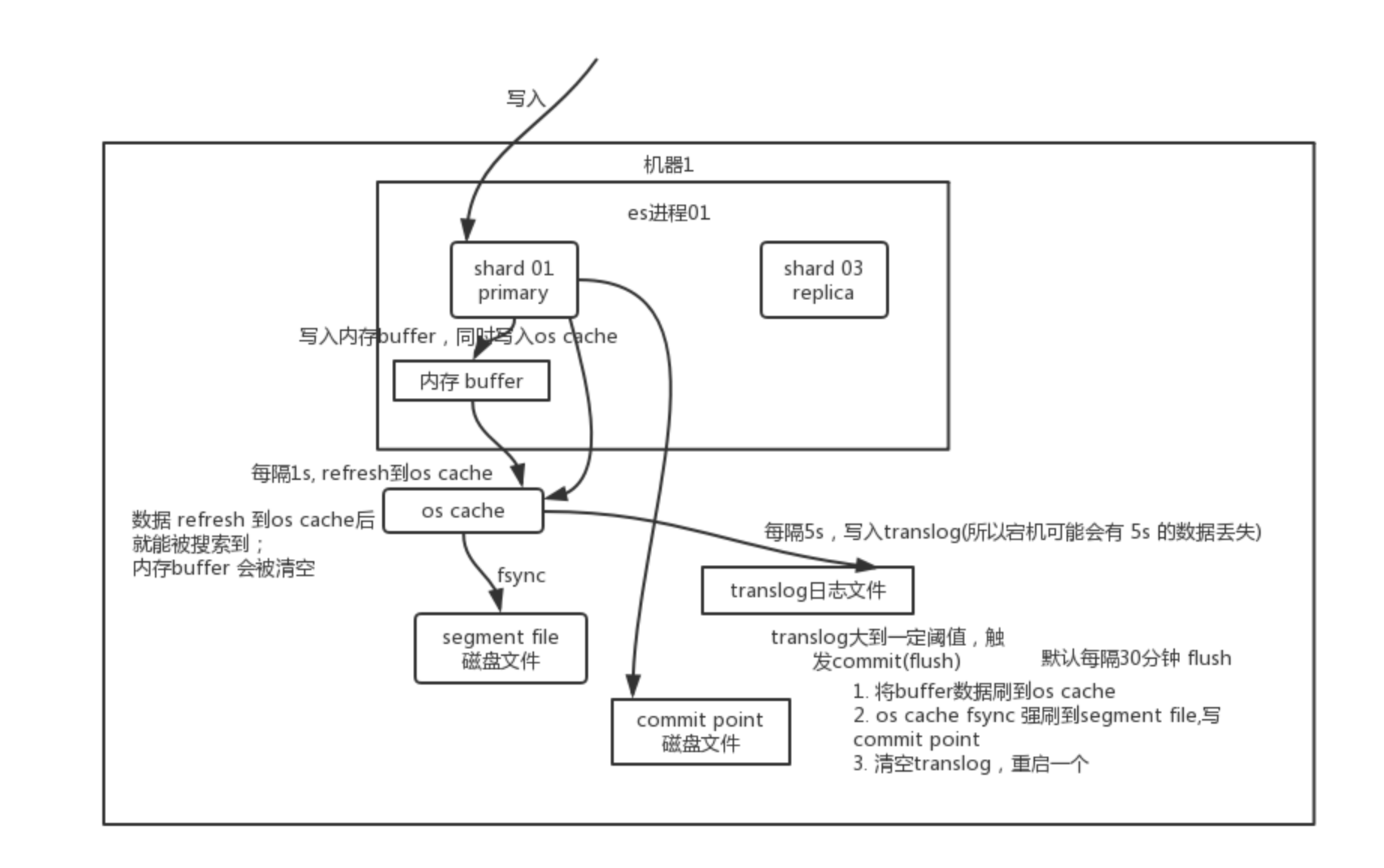
当用户向一个节点提交了一个索引新文档的请求,节点会计算新文档应该加入到哪个分片(shard)中。每个节点都存储有每个分片存储在哪个节点的信息,因此协调节点会将请求发送给对应的节点。这个请求会发送给主分片,等主分片完成索引,会并行将请求发送到其所有副本分片,保证每个分片都持有最新数据。(文档应该加入哪个分片简单来说用的是取模算法,比如说现在有个num_primary_shards个分片,这个时候传过来一个doc_id,那么默认会放在hash(doc_id) % num_primary_shards这个分片)
- 每次写入新文档时,都会先写入内存中,并将这一操作写入一个translog文件(transaction log)中,此时如果执行搜索操作,新文档还不能被索引到。
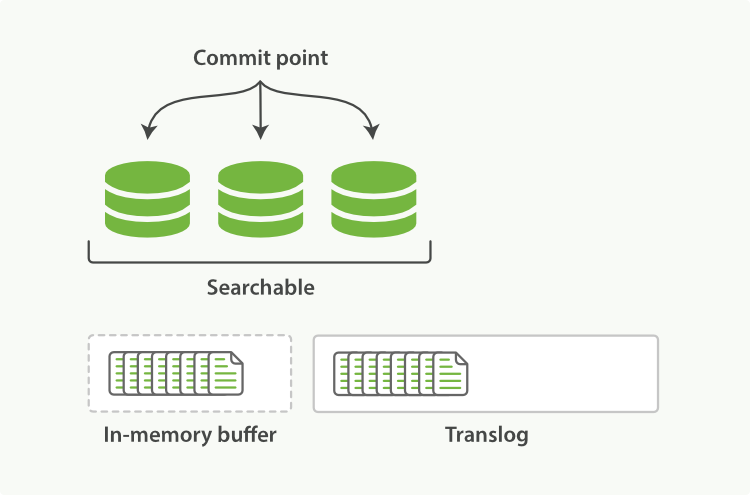
- ES会每隔1秒时间进行一次刷新操作(refresh),此时在这1秒时间内写入内存的新文档都会被写入一个文件系统缓存(filesystem cache)中,并构成一个分段(segment)。此时这个segment里的文档可以被搜索到,但是尚未写入硬盘,即如果此时发生断电,则这些文档可能会丢失。
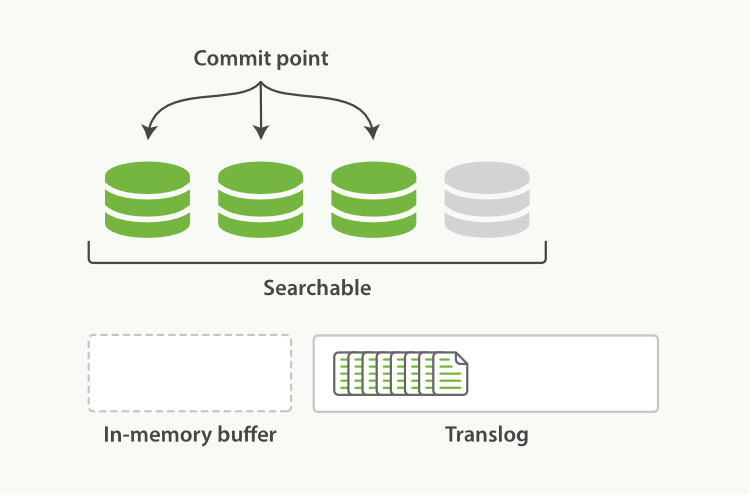
- 不断有新的文档写入,则这一过程将不断重复执行。每隔一秒将生成一个新的segment,而translog文件将越来越大。
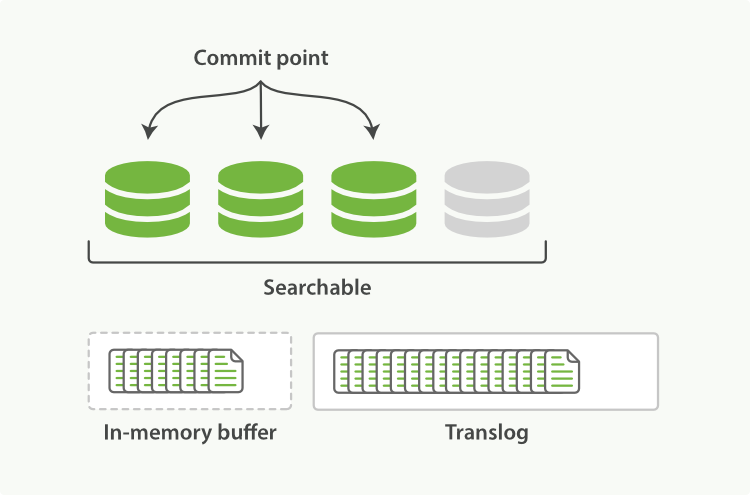
- 每隔30分钟或者translog文件变得很大,则执行一次fsync操作。此时所有在文件系统缓存中的segment将被flush入磁盘,而translog将被删除(此后会生成新的translog)。
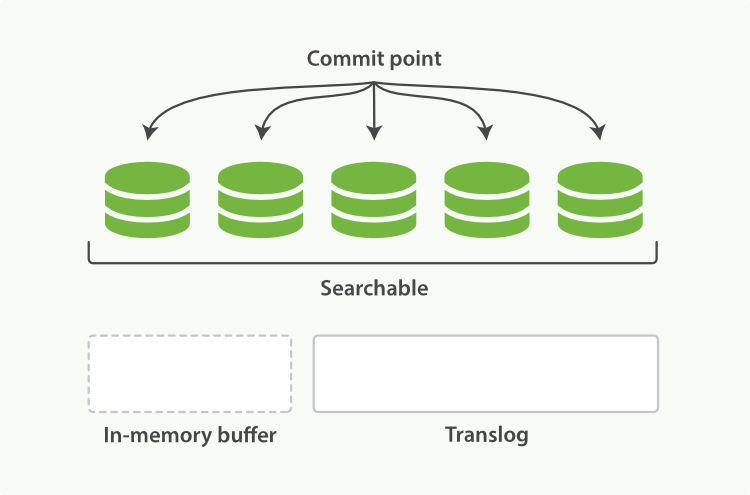
由上面的流程可以看出,在两次fsync操作之间,存储在内存和文件系统缓存中的文档是不安全的,一旦出现断电这些文档就会丢失。所以ES引入了translog来记录两次fsync之间所有的操作,这样机器从故障中恢复或者重新启动,ES便可以根据translog进行还原。
当然,translog本身也是文件,存在于内存当中,如果发生断电一样会丢失。因此,ES默认会每隔5秒时间将translog写入磁盘。也就是说,在这5秒以内,如果此时机器挂了,还是会丢失5秒的数据,但是这样的性能比较好,我们也可以将每次的操作都必须是直接fsync到磁盘,但是性能会比较差。
此外,由于每一秒就会生成一个新的segment,很快将会有大量的segment。对于一个分片进行查询请求,将会轮流查询分片中的所有segment,这将降低搜索的效率。因此ES会自动启动合并segment的工作,将一部分相似大小的segment合并成一个新的大segment。合并的过程实际上是创建了一个新的segment,当新segment被写入磁盘,所有被合并的旧segment被清除。
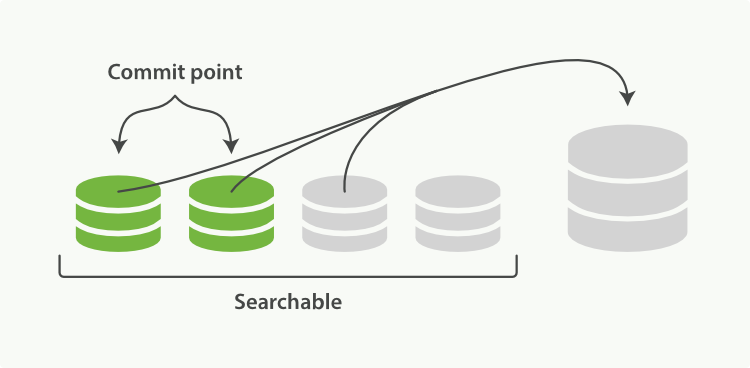
合并Segments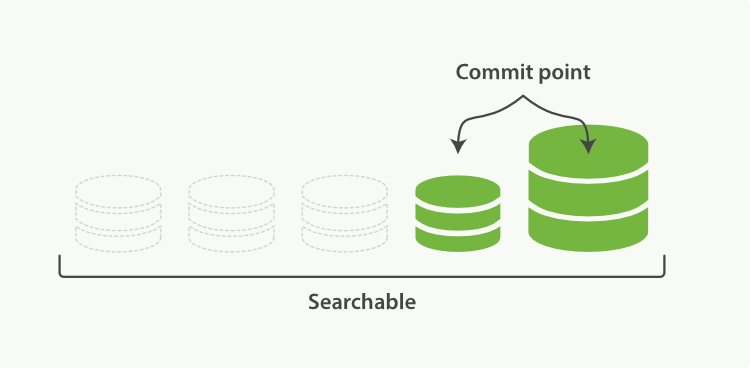
合并后删除旧segments,新segments可供搜索
查询流程
查询过程
- 客户端发送一个请求给协调节点。
- 协调节点将搜索的请求转发给当前index的所有shard,同一个Shard的Primary和Replica选择一个。
- query phase:每一个shard 将自己搜索的结果返回给协调节点,由协调节点进行数据的合并,排序,分页等操作,产出最后的结果。
- fetch phase:协调节点根据唯一标识去各个节点进行拉取数据,最终返回给客户端。
查询原理
查询过程大体上分为查询和取回这两个阶段,广播查询请求到所有相关分片,并将它们的响应整合成全局排序后的结果集合,这个结果集合会返回给客户端。
- 查询阶段
- 当一个节点接收到一个搜索请求,这这个节点就会变成协调节点,第一步就是广播请求到当前index的所有shards上,查询请求可以被某一个主分片或某一个副分片处理,协调节点将在之后的请求中轮询所有的分片来分摊负载。
- 每一个分片将会在本地构建一个优先级队列,如果客户端要求返回结果排序中从from名开始的数量为size的结果集,每一个节点都会产生一个from+size大小的结果集,因此优先级队列的大小也就是from+size,分片仅仅是返回一个轻量级的结果给协调节点,包括结果级中的每一个文档的ID和进行排序所需要的信息。
- 协调节点将会将所有的结果进行汇总,并进行全局排序,最终得到排序结果。
- 取值阶段
- 查询过程得到的排序结果,标记出哪些文档是符合要求的,此时仍然需要获取这些文档返回给客户端。
- 协调节点会确定实际需要的返回的文档,并向含有该文档的分片发送get请求,分片获取的文档返回给协调节点,协调节点将结果返回给客户端。
更新流程
更新文档会首先查找原文档,得到该文档的版本号。然后将修改后的文档写入内存,此过程与写入一个新文档相同。同时,旧版本文档被标记为删除,该文档可以被搜索到,只是最终被过滤掉。
删除流程
每一个磁盘上的segment都会维护一个.del文件,用来记录被删除的文件。每当用户提出一个删除请求,文档并没有被真正删除,索引也没有发生改变,而是在del文件中标记该文档已被删除。因此,被删除的文档依然可以被检索到,只是在返回检索结果时被过滤掉了。每次在启动segment合并工作时,那些被标记为删除的文档才会被真正删除。
参考文档
https://www.elastic.co/guide/cn/elasticsearch/guide/current/index.html
没有评论