OpenAI 发布文生视频模型 Sora,这个世界还真实吗?

本文转载至小报童专栏《AI数字人从制作到变现》。欢迎扫码订阅。

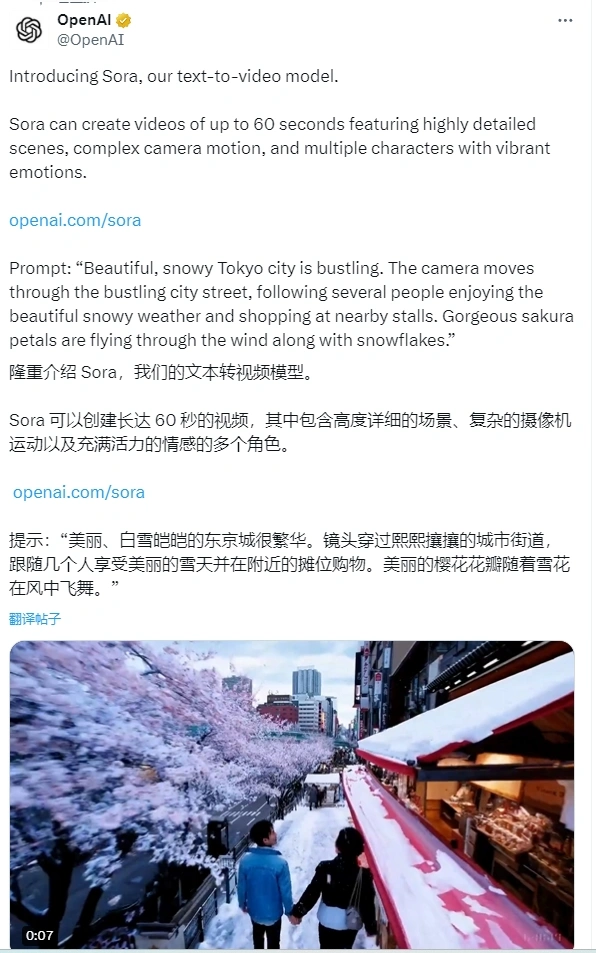
OpenAI 最近推出了一款名为 Sora 的全新视频生成模型,已经火爆全网。
OpenAI 持续推进 AI 技术,将曾属于科幻的能力变为现实。
首先推出的是 ChatGPT——展现了先进的大语言模型如何支持流畅对话。
紧接着推出 DALL-E,利用文字提示创造出令人赞叹的合成图像。
如今,他们又迈出了一大步,推出了 Sora。这款新的模型能够根据文字描述直接生成逼真的视频。

什么是 Sora?
Sora 是一个利用全新 AI 模型——扩散模型(diffusion models),从文本到视频转换的 AI 生成器。用户只需提供描述视频场景的文本提示,Sora 就能将该场景变成最长 60 秒的全动态视频。
Sora 官网:https://openai.com/sora
做为颠覆时代的AI新突破,Sora 的出现甚至引起央视的播报。
那它到底有多强?凭什么让 AI 圈整个沸腾?
只需要三个词来总结Sora,那就是:
- “60s超长长度”
- “单视频多角度镜头”
- “世界模型”
关键是只用一行字,就能做出这样的吊炸天的视频。。。
第一,60秒超长长度
Pika、Runaway 那些生成 3 秒 4 秒视频一下子就没有了市场。
Sora 能做 60 秒视频!!!
输入几句话,60 秒的精美视频直接出来,而且支持 API,这首先颠覆的就是影视行业。
一位穿着黑色皮衣、身披长款红裙、脚踩黑色靴子,手挽黑色手袋的时髦女性,在东京那些灯火辉煌、霓虹闪烁的街头自信而悠闲地行走。她佩戴太阳镜,涂着红色唇膏。街面湿润,倒映着五彩斑斓的灯光,形成一幅美丽的镜像世界。四周是络绎不绝的行人。
一句话,60s一镜到底,所有的主角,所有的背景,甚至所有的配角,都如同真实世界:

(因为小报童平台原因,没法直接展示视频,可移步下面飞书画册中观看)
比如上面 OpenAI 官方发布的这段视频就是用下面的一段文字生成的。
东京,这座雪白美丽的城市,正充满了生机。镜头穿梭在繁忙的街道上,跟随着那些沉醉在迷人雪景中、在街边摊位上选购商品的人们。随风飘舞的樱花瓣与雪花交织在一起,构成了一幅动人的画面。

(因为小报童平台原因,没法直接展示视频,可移步下面飞书画册中观看)
第二,单视频多角度镜头
你要是学过一点剪辑,就知道这是一件多么恐怖的事情。
原来你拍一段视频,好几台机器中景近景远景啥的互相切换,现在都给我闭嘴!
OpenAI 直接一句话实现了各种中景近景远景切换,在一分钟的视频里,实现了多角度,人物还无比稳定。

(因为小报童平台原因,没法直接展示视频,可移步下面飞书画册中观看)
我们来通过这短短 17s 的视频包含了哪些信息量:
第一镜,给到主角近景,包括红色羊毛编织的摩托车头盔和蓝天和由盐组成的沙漠环境都被准确表现出来
第二镜,从蓝色摇到了远景的人,再到特写出现主角色眼神,角色和第一镜保持了一致,包括角色的五官特征,毛线帽和头盔上 33 的标记都能够验证这一点,此时人物的位置关系是带着 33 号头盔的主角站在了远景角色的反方向
第三镜,出现了一个带头盔的稍年轻的角色,胡子也短了不少,他似乎是在飞船内部向外看
第四镜,镜头跟随远景的角色向前推进,画面中出现的清晰的脚印,
第五镜,飞船内的年轻角色似乎发现了有人正在走近飞船,特写推的更近了,暗示有变化会发生
第六镜,特写舱门,手从右侧入画
第七镜,特写主角眼神,增加紧张感
第八镜,特写主角侧面,此时他站在原地,看向另一侧
第九镜,太空仓内环境,各类仪表、屏幕清晰可辨。
3 个先后出现的角色一致,位置关系一致,环境一致,全程镜头都保持了手持摄影机的摇晃感,输出1920*1080,30帧/秒的高清视频。

你只需要输入文字:
一部电影预告片,展示一位30岁太空人的冒险故事,他戴着一顶红色羊毛编织的摩托车头盔,背景是蓝天和盐漠,采用电影风格,使用35毫米胶片拍摄,色彩鲜艳。
好了,一个真实的世界,一个多角度真实的视频,就出来了。
第三,世界模型:
所谓世界模型,最重要的是数据清洗和整理,是物理规则的完美复刻,在 Sora 之前,我们没见过太多完美的案例。
世界模型最大的意义在于重构所有的真实,这其中的难度可想而知。
而 OpenAI 一直以能用全世界大数据出名,ChatGPT 也一直也语料库的丰富多样性碾压一切。
如果一个视频软件用的是世界的模型,这意味着,它已经是无所不知无所不晓的怪物了。
比如下面这只猫:

(因为小报童平台原因,没法直接展示视频,可移步下面飞书画册中观看)
它抓住主人的那一刻,猫的神情、主人的神情,被子的状态,枕头的凹陷。。。。
简直不能再更真实了。
这意味着视频行业、传统的影视公司、虚拟拍摄公司、特效、广告等公司,。。。。
都得要么革新要么死掉了。
我实在想不出 OpenAI 如何在短短一年时间实现了世界模型,据说 OpenAI 随后会公开技术文档,只能让我们拭目以待了吧。
看完这些视频,我甚至有一些感觉:AGI 是不是真的快来了,人类世界是不是真的是外星人虚拟出来的世界。
OpenAI 真是一年不鸣,一鸣再次惊人。
Sora 的创意潜力演示
因为小报童平台原因,没法直接展示视频,但是大家可以点击下面的飞书画册,查看所有目前官方的视频 Demo(包含中英文提示词)。
https://esouqpttmy.feishu.cn/base/TZ8Eb98mPawyHAslY74ccxCgnHA?table=tblg0Q6XnBCVqiNw&view=vewsynMt1n
Sora 的文生图功能
Sora 除了文生视频,也能文生图像,虽不及 Midjourney,但优于 DAll·E 3。

Prompt:Close-up portrait shot of a woman in autumn, extreme detail, shallow depth of field
提示词:秋季女性特写肖像照,极其细节,浅景深
Prompt:Digital art of a young tiger under an apple tree in a matte painting style with gorgeous details
提示词:苹果树下一只小老虎的数字艺术,采用哑光绘画风格,细节华丽
Prompt:Vibrant coral reef teeming with colorful fish and sea creatures
提示词:充满活力的珊瑚礁,充满色彩缤纷的鱼类和海洋生物
结语
像 Sora 这样的模型正在开启一个充满无限可能的新世界,让有创意的人能够把他们最富有想象力的点子变为现实。随着我们踏入这场技术革命,去想象未来将带来什么,真是让人心潮澎湃。
在未来十年里,我们是不是就能仅凭一个简单的指令,就打造出个性化的电影呢?是不是我们能够利用 AI 和 Apple 的下一代工具,比如 Vision Pro,把想象中的生动场景变为触手可及的现实?
这一切现在似乎已经触手可及。技术正在一步步将昔日的科幻梦想变为现实,每一次进步都是通过一款 AI 模型实现的。
未来已不再遥不可及——它正在我们眼前逐渐展开。创意的新纪元已经到来,艺术家和创新者们正在利用这些工具创造出令人叹为观止的艺术品。
在我们继续探索和接受这些技术进步的过程中,我们不仅是变化的旁观者,更是参与塑造一个无限想象力世界的创造者。
活在这样一个充满激动人心的时代,真是太美妙了!
没有评论