数据存储中5种最常见的索引模型
数据库索引,是数据库管理系统中对一列或者多列值进行排序的数据结构。索引模型的设计,是为了在满足数据量大小、写入性能等前提下,最大化的提升数据检索效率。目前常用的索引模型有Hash表、有序数组、跳表、B+树和LSM树。本文是对每种索引模型的简要介绍,便于大家后续进一步的深入研究。
Hash表
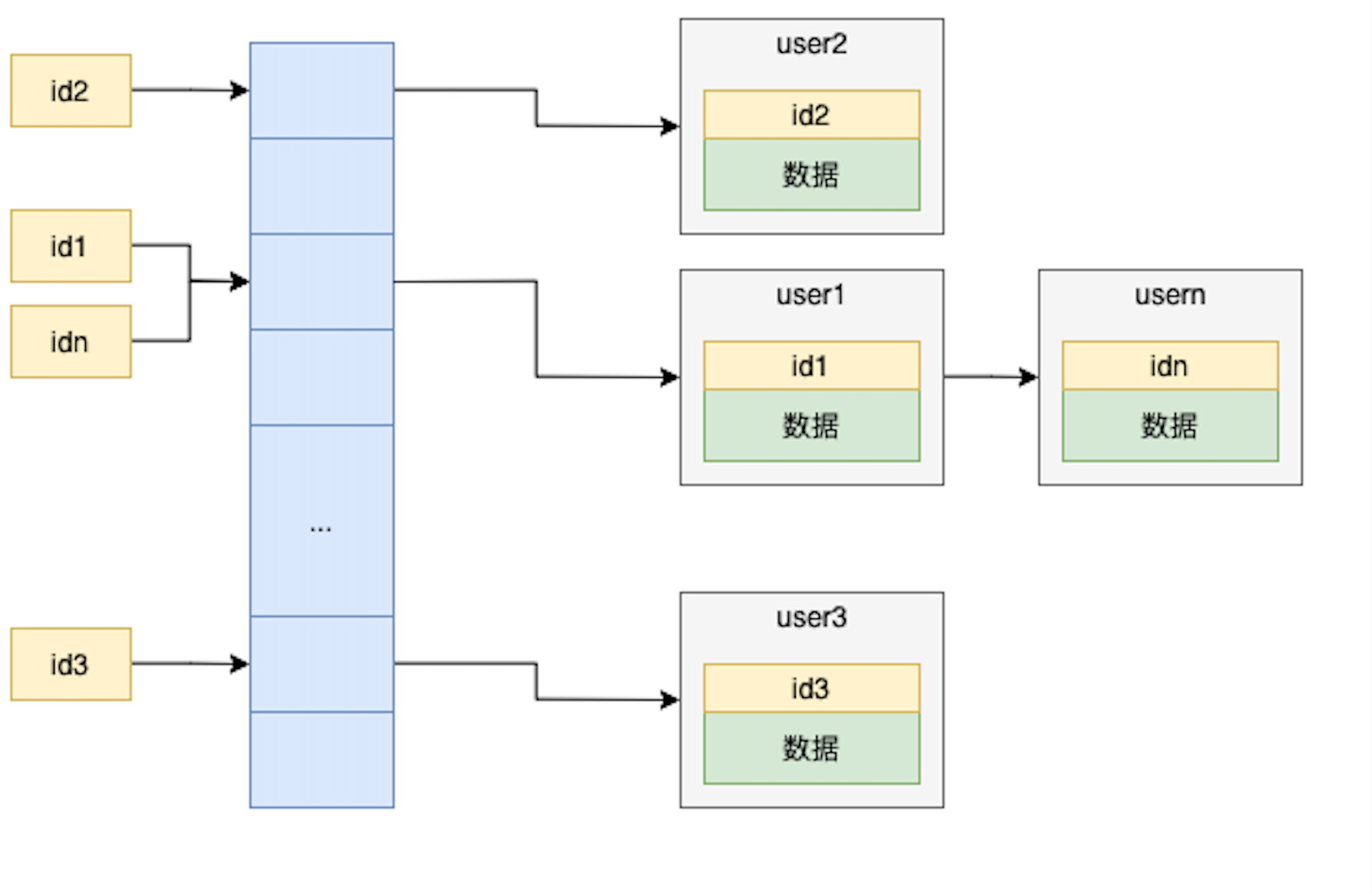
Hash表是一种key-value的存储结构,通过key计算出下标,然后将value添加到该下标对应的链表中去。哈希表这种结构适用于只有等值查询的场景(比如 Memcached 及其他一些 NoSQL 引擎),不适合区间查询。
有序数组
有序数组在等值查询和范围查询场景中的性能就都非常优秀【借助二分法】。但是缺陷也很明显,针对插入和删除场景,需要挪动后面的整个记录,代价太高。有序数组适用于静态存储引擎。比如你要保存的是 2017 年某个城市的所有人口信息,这类不会再修改的数据。
跳表
将有序数组转换为有序链表,解决插入和删除时性能低的问题;同时引入多个层级,解决链表无法二分查找的问题
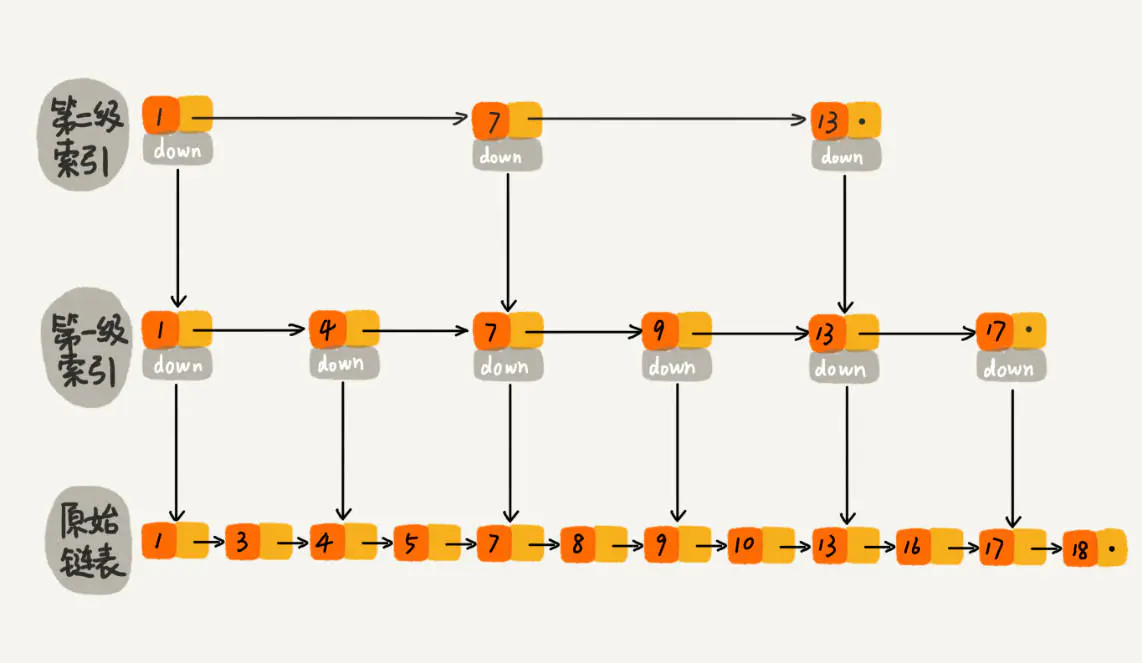
当要查找10的时候:
- 在第二级索引上从1开始往后查找,当找到7时,发现后一个值13是大于10的,所以从7开始转到第一级索引
- 从第一级索引7开始往后查找,找到9时,发现后一个值13是大于10的,所以从9开始转到原始链表查找
- 从9开始往后找,找到10
跳表适用于内存数据库【如Redis】,插入/删除/查找的效率都很高,时间复杂度为O(logN)
B+树
理论上来说,使用平衡二叉搜索树,也能达到跳表的性能。但是数据量较大时,内存中可能放不下所有的数据,必然存在“部分数据在内存,部分数据在磁盘”的情况。这种情况下如果使用跳表或者平衡二叉搜索树,则存在大量的随机磁盘访问,严重影响查询性能。但是,将平衡二叉搜索树进一步扩展成B+树,则能较好的解决这个问题。
树上的每个节点对应到磁盘上的一个数据块。
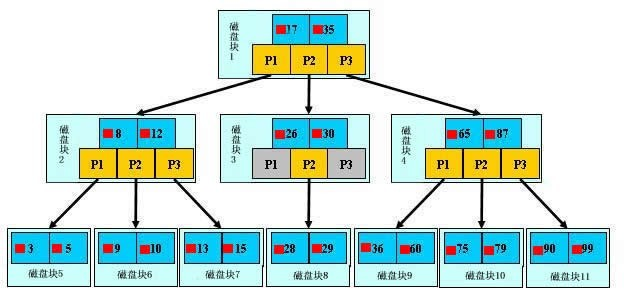
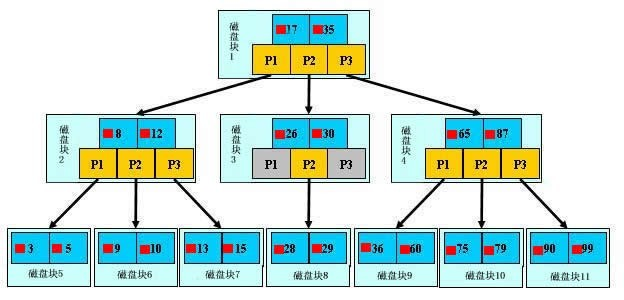
在 B+ 树中,所有数据记录节点都是按照键值的大小存放在同一层的叶子节点上,而非叶子结点只存储key的信息。由于非叶子节点只存储key而不是数据记录,所以每个非叶子节点可以存储尽可能多的key,从而降低了树的高度。树的层级越少,查询数据越快。以 InnoDB 的一个整数字段索引为例,每个节点大概有 1200各分叉。当树高为 4 时,大概可以存储17亿条数据【1200^3 ≈ 17亿】。考虑到树根的数据块总是在内存中的,从17亿条数据中查找一个值,最多只用访问3次磁盘;而树的第二层也有很大概率在内存中,那么访问磁盘的平均次数会更少。
B+ 树叶子节点的关键字从小到大有序排列,左边结尾数据都会保存右边节点开始数据的指针。
叶子节点和叶子节点间通过双向链表链接,所以历整棵树只需要遍历所有的叶子节点即可
LSM树【Log-Structured Merge-Trees】
在B+树中,每次有数据写入时,可能要插入到不同的节点,即写入不同的数据块。大量的磁盘随机写操作会影响写入速度。因此B+树不适合写入量大的场景。针对这个问题,HBase引入了LSM树的概念,将随机写转变为顺序写,大幅提升了写入速度。和B+树相比,LSM牺牲了部分读性能,用来大幅提高写性能。目前HBase/LevelDB/RocksDB/ClickHouse这些NoSQL存储都是采用的LSM树。
LSM树的结构是横跨内存和磁盘的,包含memtable、immutable memtable、SSTable等多个部分。
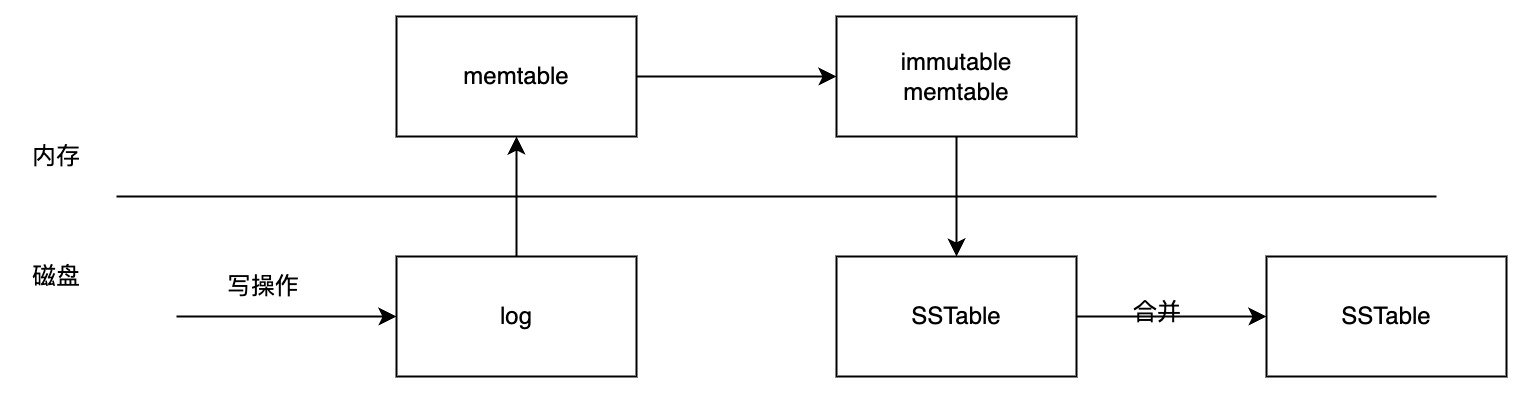
数据写入过程
- 插入、修改、删除等操作记录先append到操作日志(以便异常时恢复使用),然后再将数据写到memtable。memtable可以使用跳表或者B+等数据结构来组织数据以保持数据的有序性。
- memtable达到一定的数据量后,转化为immutable memtable,并同时生成一个新的memtable来接收新的数据。immutable memtable在内存中是不可修改的数据结构,它是将memtable转变为SSTable的一种中间状态。目的是为了在转存过程中不阻塞写操作。
- immutable memtable会刷到磁盘,形成SSTable
- SSTable是在磁盘上的有序键值对集合。为了加快SSTable的读取,可以通过建立key的索引以及布隆过滤器来加快key的查找。
- 随着immutable memtable不断刷到磁盘,SSTable会逐渐增多,因此需要对SSTable进行合并。
SSTable的合并策略
1)size-tiered 策略
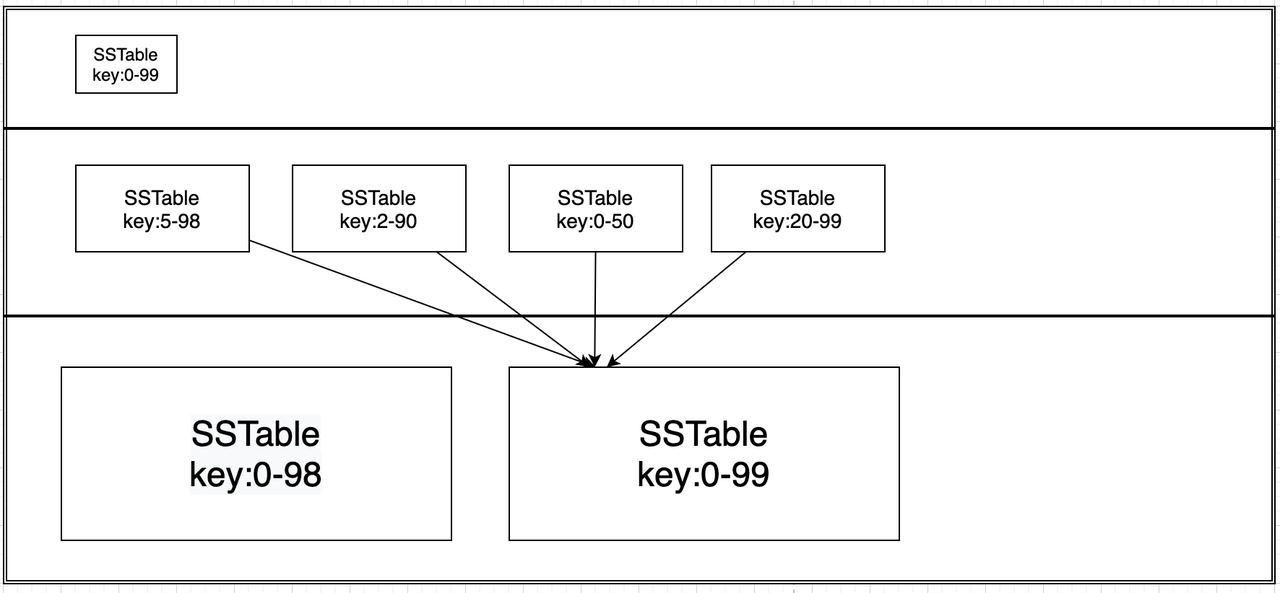
size-tiered策略保证每层SSTable的大小相近,同时限制每一层SSTable的数量。如上图,每层限制SSTable为N,当每层SSTable达到N后,则触发Compact操作合并这些SSTable,并将合并后的结果写入到下一层队尾成为一个更大的SStable。
最底层的SSTable会变得非常大,且每层中的不同SSTable中可能存在同一个key
2)leveled 策略
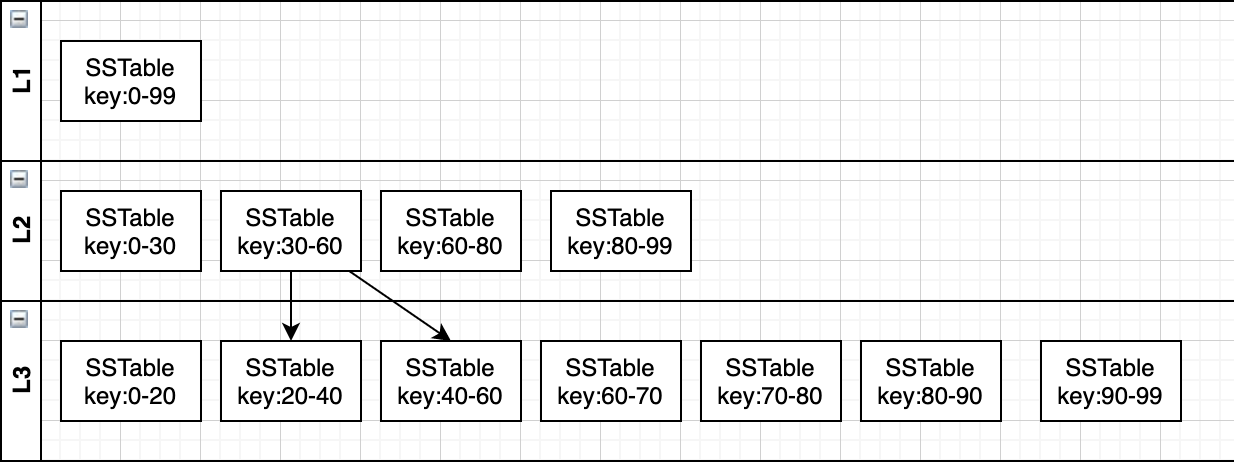
leveled策略限制了SSTable文件的大小,每一层不同 SSTable 文件 key 范围不重叠且后面的最小 key 大于前一个文件的最大 key;当每一层 SSTable 的总大小达到阈值 N 后,则触发 Compact 操作:随机选择一个SSTable,然后从下一层(下一层 key 是全局有序的)选择与当前SSTable存在重叠的SSTable进行合并
leveled 每层内key是不会重复的
数据查询过程
- 根据索引项先查memtable,再查immutable memtable,最后查SSTable
- 查询SSTable时,先从底层查起。每层查询时,如果SSTable使用size-tiered策略的话则从后向前遍历,直到找到符合条件的索引项
没有评论